2.04 关系数据库的存储与索引¶
从前面的内容,我们知道数据的存储结构和索引对数据管理系统的性能至关重要。本节将介绍关系数据系统的存储结构以及索引。
2.04.1 存储结构¶
关系数据库系统使用分页存储的方式组织数据,也就是说硬盘存储空间被划分成多个固定大小的页,数据以关系模型的结构存入数据页中。页是数据的最小存取单元,大小一般为8KB~64KB。
在关系数据库中,数据存储的方式包括行存储和列存储。图2-4-1中展示了学生表的行存储和列存储方式。
- 行存储:数据按行存储在页中,即以表中的一行数据为存储单元进行连续存储。每一行数据表示关系中的一个元组(表中的一条记录),包含该元组(记录)的所有属性。例如,学生表中的第一行记录中包含“2022001,沐辰、男、19、计算机”,这些数据在磁盘上是连续存储的,即存储在一个数据页中,相邻的行在存储位置上也是相邻的。
- 列存储:数据按列存储在页中,即以表中的一列数据为存储单元进行连续存储。一列数据表示关系中某一个属性的所有值,每一列的属性值存储在一起,不同列的属性值分开存储。例如,学生表中的“学号”列的数据存储在一个连续的区域,“姓名”列的数据存储在另一个连续的区域,每个列中的数据在存储位置上是相邻的。
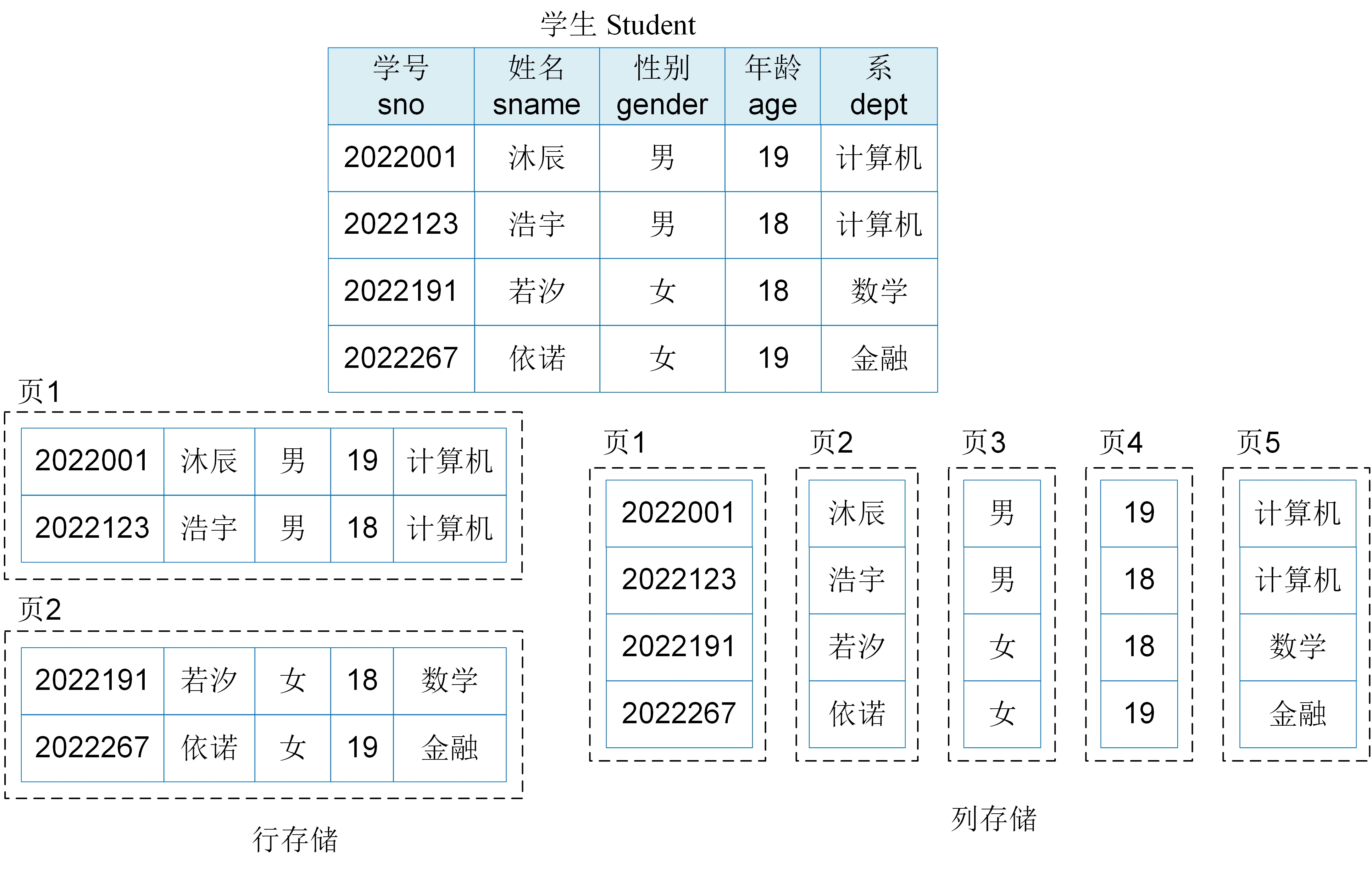
基于行存储的关系数据库系统使用主码上的聚簇B+树索引来组织数据表。数据表中的记录按照主码属性值进行排序,排序后的记录依次被存放在一个个数据页中,数据页中的记录顺序与聚簇B+树索引的叶子节点的键值顺序一致。上图2-4-1中的学生表通过“学号”主码上的聚簇B+树索引进行组织。当向学生表中插入一条新的学生记录时,首先通过聚簇B+树索引确定新记录的存储位置,然后将记录写入磁盘存储空间,最后再将新记录的主码插入B+树索引。对于简单的顺序插入(数据表的主码满足自增条件)操作来说,通常不需要通过复杂B+树索引定位,只需要在表的存储空间末尾插入新记录,再更新B+树索引结构即可。当查询姓名为“沐辰”的年龄时,如果在“姓名”列上有辅助B+树索引,则通过B+树索引找到“沐辰”所在的叶子节点,叶子节点中存储了指向实际数据行的指针,通过指针可以定位到姓名为“沐辰”的行,最后再返回该行的年龄属性值。如果在“姓名”列上没有辅助索引时,则从表的起始位置开始,依次读取每个数据页中的每行记录,然后检查每行记录的“姓名”属性是否等于“沐辰”,直到扫描完整个数据表。当将学号为“2022001”的学生系改为“数学”时,首先通过学号上的B+树索引找到学号为“2022001”的记录行,然后修改该行对应的系属性值,最后再将该行写回原存储空间。当删除学生姓名为“依诺”的学生记录时,首先通过索引或者全表扫描的方式找到姓名为“依诺”的行,然后删除该行数据,并回收该行所占的存储空间。
基于列存储的关系数据库系统通常使用类似Inode结构来组织数据表。Inode结构中记录了数据表中每个列的存储空间地址、数据类型等信息,这些信息称为元数据(Metadata)。对于上图2-4-1中的学生表,元数据中分别存储了“学号”、“姓名”、“性别”、“年龄”、“系”五个列的存储空间地址。当向学生表中插入一条新的学生记录时,首先通过元数据找到每个列存储区域的位置,然后分别在每个列区域的末尾插入对应列的数据。如果列上有索引,则更新索引结构。当查询姓名为“沐辰”的年龄时,如果在“姓名”列上有辅助B+树索引时,则通过B+树索引找到“沐辰”所在的叶子节点,叶子节点中存储了指向“姓名”列存储区域中“沐辰”的存储位置以及“沐辰”在数据表中的行号,然后根据行号到“年龄”列存储区域中读取对应的值。如果在“姓名”列上没有辅助索引时,则通过元数据找到“姓名”列存储区域的起始地址,然后依次读取每个数据页中的数据,检查是否等于“沐辰”,如果等于则记录其行号,直到扫描完整个“姓名”列存储区域,最后根据行号在“年龄”列存储区域中读取对应的值。当将学号为“2022001”的学生系改为“数学”时,首先通过索引或者顺序扫描的方式在“学号”列存储区域中找到学号为“2022001”的行号,然后根据行号在“系”列存储区域中找到对应的更新位置,最后将值更新为“数学”。当删除学生姓名为“依诺”的学生记录时,首先通过索引或者顺序扫描的方式在“姓名”列存储区域中找到姓名为“依诺”的位置和行号,然后在“姓名”列存储区域中删除“依诺”,同时根据行号分别删除在“学号”、“性别”、“年龄”、“系”四个列存储区域中的对应数据,最后回收删除数据所占的存储空间。
行存储和列存储在增删改查操作上有各自的优缺点。对于插入、更新和删除操作,行存储的效率要高于列存储。行存储以行为单位存储,只要定位到一行之后,就可以一次性对一行的所有属性进行插入、更新和删除,很容易保证数据的完整性和一致性,而列存储以列为单位存储,需要在多个列存储区域分别进行操作。而当查询只涉及表中的少数列时,列存储的效率则明显高于行存储。例如,在学生表中查询所有学生的姓名时,列存储只需要读取“姓名”列的存储区域,而行存储需要读取每一行的所有数据,从中提取姓名数据,行存储会导致大量笔不要的I/O操作。因此,行存储更适合用于具有频繁插入、更新和删除操作的在线事务处理应用仓井,行存储更适合用于具有大量数据分析操作的应用场景。另外,列存储更有利于对数据进行压缩,比行存储更能节省空间。
2.04.2 关系数据库索引¶
基于行存储的关系数据库系统默认会在主码上创建B+树聚簇索引,它只能实现基于主码属性值的高效查询,无法支持其他属性值上的高性能查询。而基于列存储的关系数据库系统默认不创建索引。为了尽可能地满足更多需求的高效查询,关系数据库系统允许在主码或者其他属性值上构建基于B+树结构的辅助索引,实现通过快速定位记录/属性值所在的数据页和行号,避免全表扫描。
关系数据库系统支持的辅助索引包括单键索引、复合索引。 * 单键索引是指在单个属性上创建索引,如唯一索引,全文索引; * 复合索引是指在多个属性上创建索引,基于复合索引的查询遵循”最左前缀索引“原则;
其中,唯一索引是指索引字段上的值在数据表中是唯一的,唯一索引用于确保数据的完整性,防止在该字段(属性)中插入重复的值。例如,在学生表的“学号”列建立唯一索引后不允许插入两个具有相同学号的学生记录。全文索引是用于对文本类型列进行索引,以支持模糊查询、关键词搜索等复杂的文本搜索功能。复合索引基于多个属性列构建的索引,例如,在学生表的“姓名”和“年龄”两列构建复合索引。数据库系统将两列值组合在一起作为索引键进行排序和存储。在B+树索引结构的叶子节点中,叶子节点首先按姓名进行排序,姓名相同的情况下再按年龄进行排序。最左前缀原则是复合索引使用的重要规则。最左前缀原则是指在查询时,只有当查询条件中使用了复合索引最左边的列时,索引才会被有效利用,也就是说只有当查询条件中至少包含姓名时,“姓名”和“年龄”上的复合索引才能利用。
2.04.3 索引的定义与删除¶
关系数据库管理系统提供了索引功能来加快数据的查询。用户可以根据应用需求在基本表上建立一个或者多个索引。
(1) 建立索引
SQL语言使用CREATE INDEX语句来创建索引,其基本格式如下:
索引可以建立在表的一列或者多列上,各列名之间用逗号隔开。创建索引时,还可以指定每个列索引值的排列次序,ASC表示升序排列,DESC表示降序排列,默认情况下为ASC。关键字UNIQUE表示建立的索引为唯一索引,即索引的每一个索引值只对应唯一的元组。CLUSTER表示建立的索引为聚簇索引。通常,一个基本表只能拥有一个主键聚簇索引。创建的索引定义会被写入数据字典中。
下例给出了在学生表上创建索引的定义:
[例2.01] 在学生表上按姓名升序创建索引。
CREATE INDEX Stusname ON Student(sname);
[例2.02] 在学生表上按姓名升序和年龄降序创建复合索引。
CREATE INDEX Stuna ON Student(sname ASC, age DESC);
(2)修改索引
对已经建立的索引,SQL语言使用ALTER INDEX语句来进行修改,其基本格式如下:
SQL
[例2.03] 在学生表的Stuname索引名改为StuN。
ALTER INDEX Stuname RENAME TO StuN;
(3)删除索引
SQL语言使用DROP INDEX来删除不必要的索引,其基本格式如下:
删除索引时,关系数据库管理系统会同时将索引的定义从数据字典中删除。练习题¶
1. 请思考,索引可以用来加速关系代数中的哪些计算?
- 仅选择
- 选择和投影
- 选择和连接
- 选择、投影、连接