1.12 文档模型¶
从本节开始,我们将介绍文档数据库管理系统的数据组织与访问。凡是将文档模型作为数据模型的数据管理系统,我们统称为文档数据库系统。
1.12.01 文档结构¶
文档模型就是将数据组织成一个个的文档。每个文档通常表示现实世界中的一个对象或实体。刚接触文档模型的读者可能会对“文档”这个词很费解,因为它跟我们通常说的文本或文章并不属同一概念。文档模型中的文档特指如下的数据组织结构:
[例1.46] 两个文档的数据组织结构
{
"sno": "2022001",
"sname": "沐辰",
"gender": "male",
"birthdate": "Jan 20, 2003",
"department": "计算机"
}
{
"sno": "2022191",
"sname": "若汐",
"gender": "female",
"birthdate": "Dec 4, 2004",
"department": "数学"
}
上例中,我们使用文档模型对”沐辰“和”若汐“两个人进行描述,得到了两个文档。熟悉Javascript或者Web编程的朋友可能会很快反应过来:这不就是JSON(JavaScript Object Notation)文件吗?没错。JSON正是使用文档模型对数据进行组织的。
在文档模型中,一个实体或对象的描述被放置在一对花括号“{”、“}”之中。花括号"{}"和描述内容则构成了一个文档。其中,描述内容为多个属性和属性值的集合。比如,关于”沐辰“的文档由学号(sno)、姓名(sname)、性别(gender)、生日(birthdate)、系(department)五个属性组成。每个属性都有一个取值(value)。其中,sname属性上的取值为“沐辰”,birthdate属性上的取值为“Jan 20, 2003”。
属性值的数据类型通常为字符串、数字、布尔值、日期、其他文档、数组和文档数组。其中,属性的取值为字符串、数组、布尔值、日期的例子如下所示:
[例1.47]
{"x":"沐辰"} /*字符串*/
{"x": 2001} /*整数*/
{"x": 3.14} /*浮点数*/
{"x": true} /*布尔值*/
{"x": Date("1988-01-09")} /*日期*/
当属性的取值为其他文档时,就形成了嵌套文档结构,如下面的例子所示:
[例1.48] 嵌套文档结构
{
"sno": "2022001",
"sname": "沐辰",
"gender": "male",
"birthdate": {
"day":20,
"month":"Jan",
"year":2003
},
"department": "计算机"
}
与例1.46相比,birthdate的属性值不再是一个字符串,而是一个文档对象,称为子文档。实际上,子文档里面还可以包含子文档。这样的嵌套可以无限进行下去,如下面的例子所示:
[例1.49] 嵌套文档结构
{
"sname": "沐辰",
"birthdate": {
"day":20,
"month":"Jan",
"year":2003
},
"father": {
"name": "沐阳",
"birthdate": {
"day":24,
"month":"Jun",
"year":1973
}
}
}
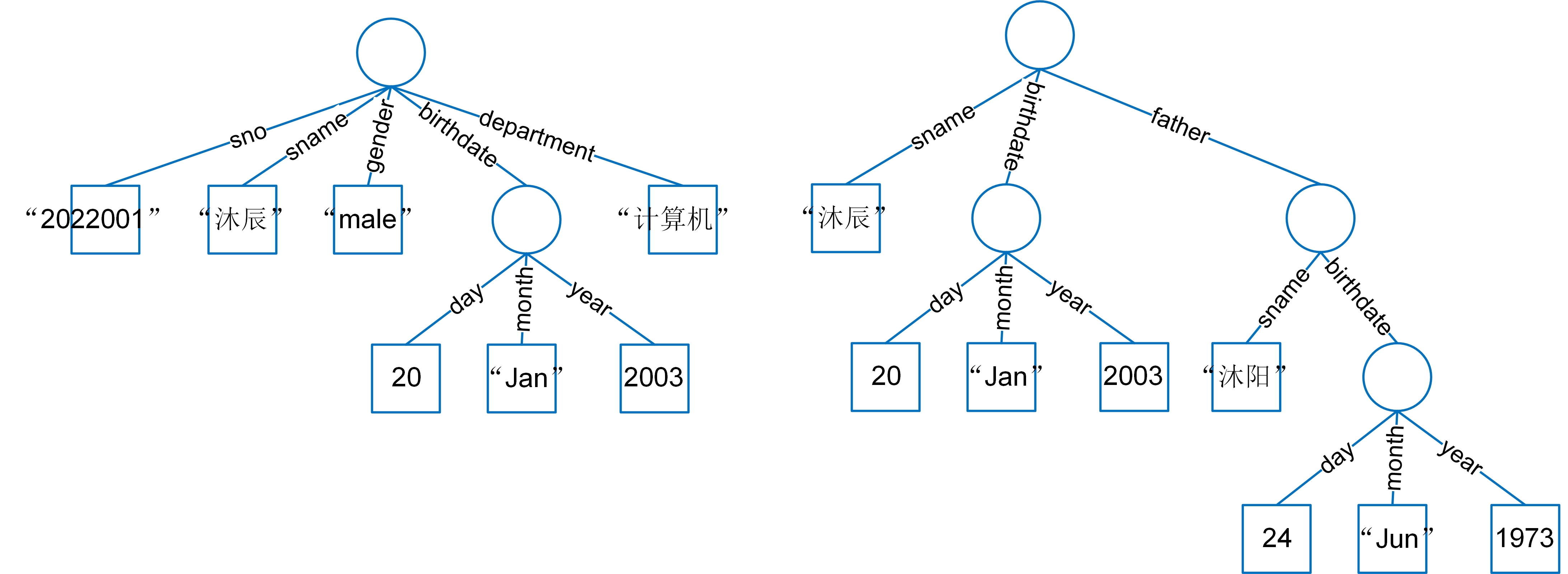
考虑嵌套之后,文档的结构就变成了树形结构。图1-12-1展示了例1.48和例1.49两个文档的树形结构。在这个结构中,树的根节点代表文档自身,叶子节点代表属性值,中间节点则代表子文档。
属性值还可以是数组的形式。例如,如果Jason Chang有三个email地址,我们就可以将它们放进一个数组里。
[例1.50] 属性值为数组的文档结构
{
"sno": "2022001",
"sname": "沐辰",
"gender": "male",
"birthdate": "Jan 20, 2003",
"department": "计算机",
"email": ["cmu@gmail.com", "cmu@163.com", "cmu@qq.com"]
}
数组里的元素除了是数值类型、字符串类型,也可以是子文档,如下例所示。有了数组之后,文档的结构仍然是树形结构。
[例1.51] 属性值为文档数组的文档结构
{
"sno": "2022001",
"sname": "沐辰",
"gender": "male",
"birthdate": "Jan 20, 2003",
"department": "计算机",
"courses": [
{
"cno":"1",
"cname": "高数",
"credit": 4,
"grade": 92
},
{
"cno":"3",
"cname": "数据库",
"credit": 4,
"grade": 85
}
]
}
在文档数据库中,文档的内容可能出现重复,以至于两个文档的属性和属性取值完全相同。为了更好地区分文档,数据管理系统通常使用一个称为“_id”的属性作为文档的标识,并确保所有文档的”_id“都是不同的。这样,用户可以通过"_id"来唯一地识别一个文档。如下例所示,"_id"属性取值采用的是12 bytes组成的ObjectID数据类型。"_id"属性通常是隐藏的,在需要时可以显示出来。
[例1.52] 文档结构中"_id"属性是文档的唯一标识
{
"_id": ObjectId("5037ee4a1084eb3ffeef7228"),
"sno": "2022001",
"sname": "沐辰",
"gender": "male",
"birthdate": "Jan 20, 2003",
"department": "计算机"
}
{
"_id": ObjectId("4b2b9f67a1f631733d917a7a"),
"x": 3.14
}
1.12.02 文档的匹配¶
文档模型是一种数据组织结构,也是人和计算机表达信息的一种共同方式。有了这种共同的表达方式,人和计算机可以对数据达成一致的理解。除了一个统一的信息表达方式,我们还需要一种统一的计算方式,用于描述数据的存取功能。文档模型上最常用的计算方式称为文档匹配。接下来,我们将描述文档是如何进行匹配的。
回到最初的例子,假设数据库里有描述"沐辰"和“若汐”的两个文档:
{
"sno": "2022001",
"sname": "沐辰",
"gender": "male",
"birthdate": {
"day":20,
"month":"Jan",
"year":2003
},
"department": "计算机"
}
{
"sno": "2022191",
"sname": "若汐",
"gender": "female",
"birthdate": {
"day":4,
"month":"Dec",
"year":2004
},
"department": "数学"
}
那么,下面这个文档能够和上面的哪个文档实现匹配呢?
直观地评判,答案显然是关于“若汐”的文档。用于匹配的文档只设定了gender和department两个属性,它和“若汐”的文档在这两个属性上的取值完全一致。通常,如果文档A的所有属性都在文档B中出现,并且两个文档在这些属性上的取值一致,那么我们可以称文档B是文档A的匹配。按照这个逻辑,下面这个文档则无法在数据库中找到匹配。
匹配的计算方式可以延申到嵌套的文档,比如将下面的文档作为匹配对象:
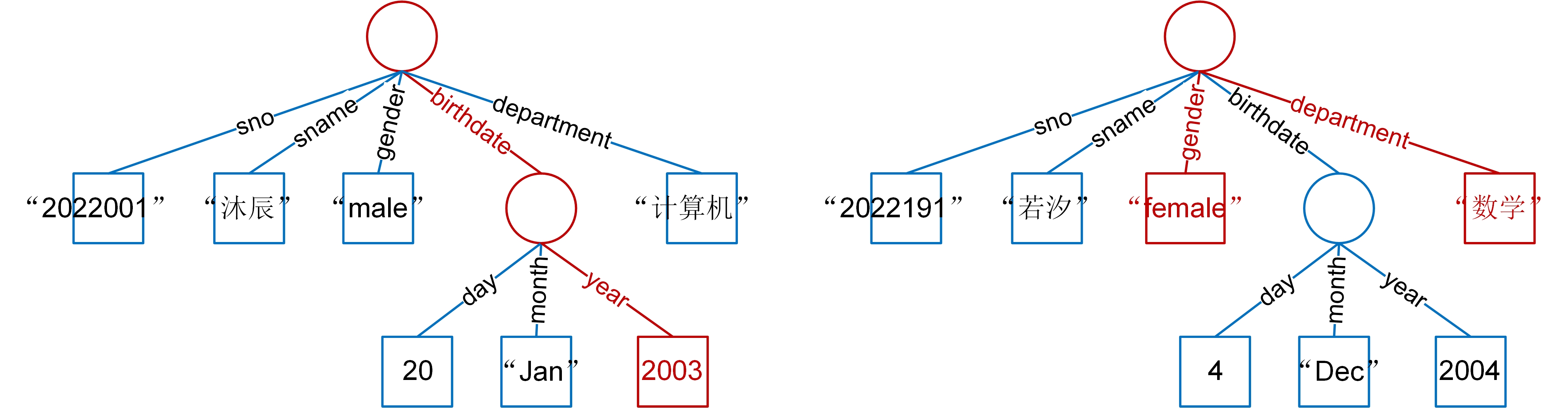
直观判断,它可以和数据库中描述“沐辰”的文档匹配。这个文档设定了属性birthdate的子属性year的取值(简称birthdate.year上的取值)。这个取值正好和“沐辰”的文档在相应属性上的取值一致。如果我们将文档看成树状结构,如果文档A是文档B的匹配,当且仅当B一定能通过对A剪枝而得到。如图1-12-2所示,红色部分的树和整棵树形成匹配,也就是说,红色部分的树可以通过去掉蓝色部分得到。
有时候,我们可以不对匹配对象的属性设定精确取值,而只设定一个取值范围条件。只要其他文档在相同属性上的取值满足这个条件,则可以形成匹配。比如,下面这个文档匹配对象:
该文档声明自己在birthdate.year上的取值大于2003。根据匹配条件进行检索,它和“若汐”的文档形成匹配,因为J“若汐”在birthdate.year上的取值为2003,满足该匹配条件。
文档匹配实际上提供了一种查询方式,让我们可以在多个文档中找到满足匹配条件的文档。
练习题¶
1. 一个文档数据库里面有两类对象,书(book)和人(person)。书和人之间存在一种写作的关系,即某个人是某本书的作者。请问这种写作关系的信息应该如何存放?
- 在描述书的文档中增加一个“作者(author)”属性,取值为其作者的名字。
- 在描述人的文档中增加一个“著作(writing)”属性,取值为其著作的标题。
- 在描述书的文档中增加一个“作者(author)”属性,取值为其作者的ID。
- A和B均可。
2. 关系数据库让用户自行定义每一张表的Primary Key(主键),用于唯一识别表中的每一行数据。例如,学生表Student(sno, sname, birthday, gender)的主键可定义为sno,宿舍表rooms(dorm_no, room_no,size, floor)的主键可定义为(dorm_no, room_no) (由宿舍号和房间号组成的复合主键)。在文档数据库中,用户无需定义主键,每一个文档都可以由系统自动产生的缺省ID进行识别。换句话说,文档数据库的ID属性起到了Primary Key的作用。请思考:关系数据库的Primary Key机制和文档数据库的ID机制有什么不同,各自的优缺点是什么?