2.02 数据的存储方式¶
上一节介绍了计算机的存储设备以及它们的工作方式。本节介绍数据是如何在存储设备中被存放和组织的。
数据是用来描述现实中的事物的。现实中的事物有个体和群体之分,比如说一个人和一群人、一本书和一套书等。因此,数据也有数据项(Data Item)和数据集(Data Set)之分。通常,一个数据项记录了一个个体,一个数据集记录了一个群体。本节使用最简单的数据模型 - “键值对” - 为例,简述数据项和数据集在存储设备中是如何被存放和组织的。
2.02.1 数据项的存储结构¶
数据管理系统的首要责任是妥善保存数据。在当代的数据存储体系结构中,一个应用的全量数据会被存放于磁盘或固态硬盘中(统称为硬盘)。离线存储和云存储由于访问速度过慢,通常只用于备份数据,以防数据丢失。而硬盘之上的内存、缓存等设备由于造价昂贵,通常只用做缓存(Cache),暂时存放那些被经常访问的数据的热点数据(hot data)。并且内存和缓存不具有持久性,当计算机断电后设备中的数据会丢失,这也导致它们不适用于长期存储数据。随着技术发展,这种存储配置方式可能发生改变。但本书为了避免内容过于发散,将硬盘作为全量数据持久存储的基本设备。
那么,数据项(这里以键值对为例)是如何被存储在硬盘中的呢?一个数据项的大小通常不固定,小到十几个Bytes,大到数KB甚至数MB。被存储下来的数据项可能随时被访问,被修改,以至于其大小随时会发生改变。一块硬盘可以看作一个连续地址上的存储空间。数据管理系统需要将众多数据项有组织地放置在硬盘中,既能有效利用存储空间,又便于数据的访问。这就需要一个高效的存储组织结构。
一种最简单的数据组织方式是将数据项逐个写入到连续的硬盘空间中。这种看似简单的方式并不利于存储空间的管理。紧挨着依次存放的数据项可能会随时被修改。一旦一个数据项的大小增长,原有的位置将无法容纳它,系统不得不重新为它分配一个位置空间。一个数据项的删除、移动或缩小会使得其原来占据的位置空间变成空洞。空洞如果得不到重复利用,不仅造成空间浪费,还会降低数据访问访问的效率。久而久之,随着数据被频繁删改,空洞的情况会愈加严重,系统整体性能会随之下降。于是,系统就需要定期对硬盘空间进行整理,去除空洞。但整理过程会耗费大量的时间和资源,可能导致系统性能的不稳定。
当代的数据管理系统更常采用的数据组织方式是将硬盘存储空间划分成多个固定大小的区域,称为页(Page)(有时候也被称为块(block)。但为了和前文中存储设备的数据存取单位有所区分,我们将软件对存储空间的划分单位称为页),并以页为单位管理整个硬盘存储空间。也就是说,数据项被打包存放在一个个的数据页中,而每个数据页被作为一个独立的存储空间来管理。当数据项被修改或删除时,系统只需要整理该数据项所在的页,而不用影响其他的页。系统在分配和回收硬盘存储空间时,只需要按页进行分配和回收就可以了。这种方式使得硬盘空间的管理变得简单且高效。
其实,数据的存放可类比于衣帽鞋袜的存放。硬盘就好比是我们的衣柜。如果直接将所有的衣帽鞋袜简单堆放在衣柜中,衣柜的空间将得不到充分利用。使用一段时间之后,我们还需要对衣物进行重新规整。而整理整个衣柜既费时又费力。一种更为合理的方式是在衣柜中使用收纳箱,将衣物分类存放在各个收纳箱中,独立管理。所有收纳箱整齐地存放在衣柜中,这样既整洁又便于使用。
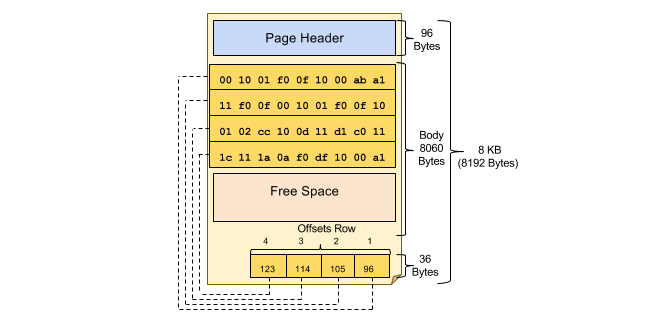
数据页的内部通常使用一些简单的结构对数据项进行组织。图2-1-4刻画了一个典型的数据页的内部空间布局。一个数据页通常包括三个部分:头部的“页头”(Page Header)、中间的数据存储空间、以及尾部的指针列表。其中,页头记录了数据页的基本信息,包括其中存放了多少数据项,还剩多少空闲空间(Free Space)等。指针列表记录了每个数据项在页中的存放位置。当用户访问数据项时。数据管理系统首先找到数据项所在的页,然后将整页数据读入内存,之后再通过页尾的指针列表找到想要的数据项。所以,页也是数据管理系统对数据进行存取的基本单位。相比于存储设备的数据存取单位 - 块,页通常更大;一个页通常包含整数个块。
另一方面,既然计算机的存储设备都是以“块”为单位存取数据的,那么以“页”为单位来管理存储空间也能更好地发挥存储设备的访问效率。(通常页的大小是块的整数倍。)即便不分页,每次访问硬盘上的数据仍然要整块地进行数据读写。何不以页为单位来组织和存取数据,有意识地将相关联的数据放在同一页中,尽可能发挥存储设备的吞吐性能。
2.02.2 数据集的存储结构¶
一个数据集包含多个数据项,并且数量可以达到成千上亿。如上所述,多个数据项可以被存放在同一页中。但一个数据页通常无法容纳整个数据集。数据管理系统需要用多个数据页来共同存储一个数据集, 并将这些数据页组织串联起来,作为整体进行管理。
对数据集的存储和管理可以仿照文件系统对文件的存储和管理。在文件系统中,每个文件对应一个Inode结构。Inode中包含了文件的基本信息和指向文件页的指针,这些信息也称为文件的元数据。图2-2-2展示了Inode的简单结构,其中,基本信息包括Inode编号、文件类型、文件权限、文件大小、文件修改和访问的时间等。Inode编号具有唯一性,文件系统可以通过编号来识别不同的文件。Inode中的地址指针指向存储文件内容的数据页。一个Inode的大小通常是128B或者256B,它能容纳的指针数量有限。然而,一个文件可能很大,包含很多个数据页。因此,Inode不仅包含直接指针还包含间接指针。每个间接指针指向一个指针页,该页中存放的全是地址指针,每一个都指向存储文件内容的数据页或者另一个指针页。指针页的使用保证了Inode可以记录成千上万的数据页,让一个文件可以存储TB级别大小的数据内容。此外,文件系统还提供了一个记录文件名与Inode编号映射关系的数据结构,称为目录项。用户通过文件名读取文件内容时,系统首先访问目录项,找到文件名对应的Inode编号,然后通过Inode编号查询到文件对应的Inode结构,最后根据Inode中的指针读取文件中的数据。

同样地,数据管理系统可以为每个数据集维护了一个类似Inode的结构,存储数据集的基本信息,如数据集的编号、大小、以及其数据页的地址指针。另外再维护一个目录项,将数据集的名称与编号的映射关系存储在目录项中,如图2-2-3所示。当数据管理系统启动时,会首先将硬盘中的目录项读入内存,通过目录项能够确定任意一数据集对应的Inode,然后通过Inode定位数据页并访问数据。

假设我们有一个记录个人信息的数据集,取名为Person。数据集中的每个数据项都记录了一个人的信息。假设我使用如下的键值对结构存储个人信息:
其中,PersonID为键,可以用来唯一地识别一个人(比如,可将其理解为身份证号码);PersonInfo记录了这个人的信息,包括他的名字、年龄等。一个人的PersonID和PersonInfo共同构成一个数据项,被存放在Person数据集中。
如果我们要通过一个人的PersonID去查找这个人的信息,数据管理系统可以通过以下过程实现。系统首先从数据集的目录项中找到person数据集所对应的Inode结构,再根据Inode中的指针找到person数据集的所有数据页,然后依次将这些页读入内存,通过数据页尾部的数据项指针找到一个个的键值对,将它们的PersonID逐个与已知的PersonID进行对比,最终找到匹配的键值对,并返回它的PersonInfo。
如果我们要对一个人的信息进行更新,可以首先通过以上过程找到被更新的数据项,在内存中对它所在的数据页进行修改,最后再将该数据页写回到硬盘。如果要删除一个人的信息,可以使用同样的步骤。如果我们要将一项新的个人信息插入到数据集中,则可以先找到数据集的Inode结构,根据Inode的内容找到第一个有空闲空间的数据页,再将数据项插入到该页中。如果所有数据页都没有足够的空间了,就向数据管理系统申请一个新的数据页,并将其加入到Inode结构中。(同文件系统一样,数据管理系统也有一个空闲存储空间的管理装置,用于分配和回收空闲的数据页。其具体实现方式与文件系统类似。这里不再赘述。)
可见,通过如上的存储组织结构,我们就实现了数据的创建、查询、更新和删除功能(即CRUD操作)。这样,一个简单的数据管理系统就成形了。
但现实中数据管理系统使用的存储组织方式远比以上的方式复杂。如上一章所述,不同的数据管理系统采用了不同的数据模型。在这些模型中,数据项和数据集的含义和结构都是不同的。比如,在关系模型中,一张表格可以被视为一个数据集,其中每个数据项既可以对应表格中的一行数据,也可以对应一行数据中的单个取值。又比如,在图模型中,一张图可以被视为一个数据集,其中每个数据项既可以对应图中的顶点(Vertex),也可以对应图中的边(Edge)。此外,不同数据模型提供的数据访问语言和数据访问方式也是不同的。虽然我们通常都通过上述的分页模式实现数据的存储,但需要根据这些模型的数据访问特点对页的大小、页的内部结构以及多页之间的数据划分方式进行针对性设计,从而让数据的访问性能满足应用的要求。
从上一节的内容中,我们可以看到不同层的存储介质之间的巨大性能差异,以及不同数据访问方式(例如顺序读写和随机读写)之间的潜在性能差异。数据的存储结构基本上决定了系统对数据的访问方式,因此对数据管理系统的性能是至关重要的。 本书会在本章后面的小节中深入介绍各类数据管理系统的特殊存储技术。
练习题¶
1. 大部分系统都是对存储空间进行分页管理的。请问,分页模式的优势不包括?
- 有利于减少存储空间的碎片化,提升空间利用率。
- 有利于提升数据访问的性能。
- 有利于提升内存缓存的效率。
- 有利于减少空间管理的成本(即减少空间管理对CPU和内存资源的消耗)。
2. 如本章提到的,内存由于比较昂贵且无法持久地保存数据,通常只作为数据缓存。那么,什么数据不适合被放在缓存中?
- 经常被修改的数据
- 像Inode这样的组织结构数据
- 刚被插入的数据
- 刚被删除的数据
3. 思考题:当我们对存储空间进行分页管理的时候,页的大小通常是一个设计要点。有的数据管理系统选择使用比较小的页,如2KB或4KB。而另一些系统会使用比较大的页,比如4MB或8MB。请问:小页面对什么情况有利?大页又对什么情况有利?我们确定页的大小时应该考虑哪些因素?
4. 思考题:如本章提到的,内存通常被数据管理系统作为缓存使用。缓存的数据单元可以有不同的选择;可以是页,即当访问完一页后,将整个页继续保留在内存中,以期后面再次访问该页就无需再从硬盘获取;也可以是数据项,即当访问完一页中的某个数据项后,将这个数据项继续保留在内存中,而将页移除,以期后面再次访问该数据项时无需再从硬盘获取。请问:页缓存和数据项缓存各自的优势和劣势是什么?什么情况下,我们可以考虑使用数据项缓存?