CS61C Lecture 10 函数调用与内存管理
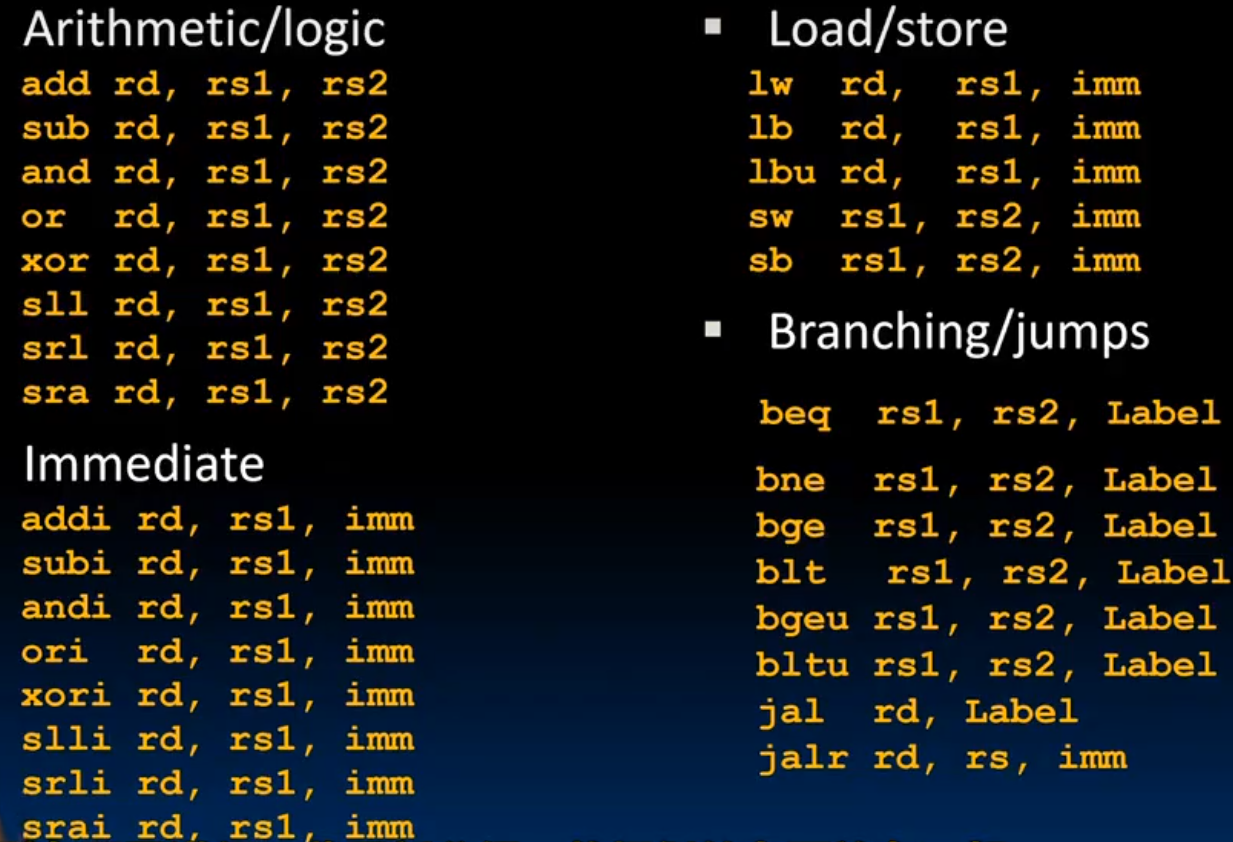
一、RISC-V函数调用核心机制
1. 寄存器保存策略
- Caller-saved寄存器 (t0-t6)
调用函数前由caller保存(如将参数存入a0-a7),可能被callee覆盖 - Callee-saved寄存器 (s0-s11)
被调函数若需要使用,必须保存原始值并在返回前恢复 - 特殊寄存器
ra (x1):保存返回地址
sp (x2):栈指针
fp (x8):帧指针(可选)
2. 堆栈帧(Stack Frame)结构
| 内存区域 | 内容示例 | 大小 |
|---|---|---|
| 高地址 → | Caller的保存寄存器 | 变长 |
| ↓ | 局部变量 | 变长 |
| 返回地址 (ra) | 8字节 | |
| 旧帧指针 (fp) | 8字节 | |
| sp → | 参数空间(需要时) | 变长 |
典型操作示例:
func:
addi sp, sp, -32 # 分配32字节栈空间
sd ra, 24(sp) # 保存返回地址
sd s0, 16(sp) # 保存callee-saved寄存器
# ... 函数体 ...
ld s0, 16(sp) # 恢复寄存器
ld ra, 24(sp)
addi sp, sp, 32 # 释放栈空间
jr ra
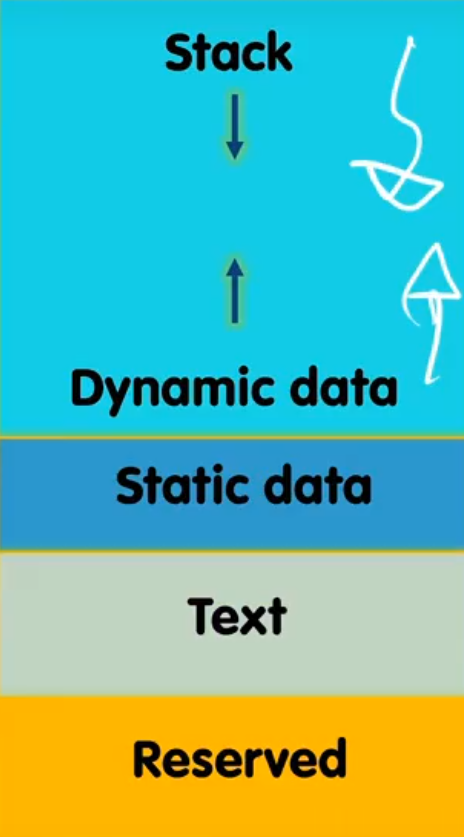
二、内存管理深度解析
1. 三大内存区域对比
| 区域 | 增长方向 | 存储内容 | 管理方式 |
|---|---|---|---|
| 栈 | 向下 | 函数调用记录/局部变量 | 自动 |
| 堆 | 向上 | 动态分配内存(malloc/new) | 手动/GC |
| 静态区 | - | 全局变量/static变量/字符串常量 | 编译器 |
 | |||
| ### 2. 内存对齐规范 | |||
| - 16字节对齐原则:RISC-V要求所有内存访问地址必须是数据大小的整数倍(如8字节数据需8字节对齐) | |||
| - 典型对齐错误示例: | |||
三、关键概念拓展
1. 过程调用标准(Procedure Call Standard)
- 参数传递规则:
- 前8个参数通过a0-a7传递
- 超过8个参数使用栈传递(从右向左压栈)
- 返回值始终存放在a0/a1寄存器
2. 堆栈操作优化技巧
- Leaf Function优化:不调用其他函数的最底层函数可不保存ra寄存器
- 帧指针省略:通过精确计算sp偏移可省略fp寄存器(需编译器支持)
3. 内存管理高级话题
- 栈溢出检测:通过MMU设置保护页(Guard Page)
- 堆碎片问题:通过内存池(Memory Pool)优化
- Alloca函数原理:动态调整栈空间
四、典型场景分析
递归函数调用示例
对应的栈变化:| ... |
| n=3 | ← sp
| ra=0x1004 |
-------------
| ... |
| n=2 | ← new sp
| ra=0x2008 |
-------------
| n=1 | ← base case
五、关键总结
- 函数调用时必须遵守的寄存器保存规则是程序正确性的基石
- 栈帧大小需同时考虑:保存寄存器 + 局部变量 + 参数传递 + 对齐填充
- RISC-V内存布局设计保证了:
- 栈堆相向增长可最大化利用内存空间
- 16字节对齐提升访存效率
- 现代编译器通过栈帧优化平均可减少30%-50%的栈空间使用
六、自我检测问题
1. 当函数参数超过8个时,第9个参数如何传递?
在RISC - V架构中,前8个整数参数(或指针)通过寄存器a0 - a7传递。当函数参数超过8个时,第9个及后续的参数会通过栈来传递。调用者需要将这些额外的参数依次压入栈中,然后被调用函数从栈上读取这些参数。
以下是一个简单的示意代码(伪代码):
# 调用者代码
def caller_function():
# 准备前8个参数
a0 = 1
a1 = 2
a2 = 3
a3 = 4
a4 = 5
a5 = 6
a6 = 7
a7 = 8
# 第9个参数
param9 = 9
# 将第9个参数压入栈
stack_push(param9)
# 调用函数
callee_function()
# 被调用者代码
def callee_function():
# 从寄存器获取前8个参数
arg1 = a0
arg2 = a1
arg3 = a2
arg4 = a3
arg5 = a4
arg6 = a5
arg7 = a6
arg8 = a7
# 从栈上获取第9个参数
arg9 = stack_pop()
# 函数处理逻辑
result = arg1 + arg2 + arg3 + arg4 + arg5 + arg6 + arg7 + arg8 + arg9
return result
2. 为什么保存寄存器时要使用sd/ld而不是sw/lw?
sd(Store Doubleword)和ld(Load Doubleword)用于处理64位数据,而sw(Store Word)和lw(Load Word)用于处理32位数据。- 在64位的RISC - V架构中,寄存器是64位的。如果使用
sw/lw来保存和恢复寄存器,只能保存或加载寄存器的低32位,高32位的数据会丢失。为了完整地保存和恢复寄存器的64位内容,就需要使用sd/ld指令。
3. 如果函数中同时需要保存s0 - s3和a0 - a3,栈空间应该如何分配?
在RISC - V架构中,每个寄存器是64位(8字节)。s0 - s3有4个寄存器,a0 - a3有4个寄存器,总共需要保存8个寄存器。 栈是向下增长的,所以需要为这8个寄存器分配的栈空间大小为8 * 8 = 64字节。 可以按照如下步骤分配栈空间:
1. 首先,将栈指针`sp`减去64,为保存的寄存器分配空间。
2. 然后,使用`sd`指令将`s0 - s3`和`a0 - a3`依次保存到栈上。
3. 在函数返回前,使用`ld`指令从栈上恢复这些寄存器的值。
4. 最后,将栈指针`sp`加上64,释放栈空间。
4. 设计一个栈帧结构,要求能同时保存3个局部变量(每个8字节)和2个需要保存的寄存器
栈帧是函数调用时在栈上分配的一块内存区域,用于保存局部变量、寄存器等信息。以下是一个满足要求的栈帧结构设计:
偏移量(从栈指针sp开始) | 内容 |
|---|---|
| 0 | 第一个需要保存的寄存器 |
| 8 | 第二个需要保存的寄存器 |
| 16 | 第一个局部变量 |
| 24 | 第二个局部变量 |
| 32 | 第三个局部变量 |
下面是一段简单的RISC - V汇编代码示例,展示如何分配和使用这个栈帧:
# 函数开始
function_start:
# 分配栈空间
addi sp, sp, -32 # 为栈帧分配32字节空间
# 保存寄存器
sd s0, 0(sp) # 保存第一个寄存器
sd s1, 8(sp) # 保存第二个寄存器
# 初始化局部变量
li t0, 1 # 第一个局部变量的值
sd t0, 16(sp) # 保存第一个局部变量
li t0, 2 # 第二个局部变量的值
sd t0, 24(sp) # 保存第二个局部变量
li t0, 3 # 第三个局部变量的值
sd t0, 32(sp) # 保存第三个局部变量
# 函数处理逻辑
# 恢复寄存器
ld s0, 0(sp) # 恢复第一个寄存器
ld s1, 8(sp) # 恢复第二个寄存器
# 释放栈空间
addi sp, sp, 32 # 释放栈帧空间
# 函数返回
ret
在这个栈帧结构中,首先分配了32字节的栈空间,然后依次保存了2个寄存器和3个局部变量。在函数结束时,恢复寄存器并释放栈空间。